
Imagínese trabajar en un proyecto importante y sufrir un tiempo de inactividad o una ralentización en los últimos momentos cruciales. Peor aún, si conduce a la pérdida de datos, es posible que tenga que empezar de nuevo.

Según Tendencias en Protección de Datos 2022, las organizaciones informaron de una tolerancia al tiempo de inactividad de “una hora o menos” para el 56% de sus aplicaciones de alta prioridad y el 49% de sus aplicaciones normales. También constata que los periodos de inactividad o las interrupciones son frecuentes: el 40%, es decir, 2 de cada 5 servidores, han sufrido una o más interrupciones en los últimos 12 meses.
Estos problemas se producen por diversas razones, y un enfoque tradicional o reactivo a menudo conduce a que el problema pase factura a todo el sistema. Si este problema se hubiera previsto o detectado con antelación, se habrían reducido al mínimo las posibilidades de que tuviera repercusiones en el sistema.
Aquí es donde la supervisión proactiva desempeña un papel crucial. La supervisión proactiva y la gestión de alertas forman una parte importante de las hojas de ruta de DevOps.
En este artículo, nos adentramos en el núcleo de la supervisión proactiva, desentrañamos su significado y exploramos las principales herramientas de supervisión proactiva que puede utilizar para aplicar este enfoque.
¿Qué es la vigilancia proactiva?
La supervisión proactiva es un enfoque global de la gestión de sistemas informáticos que consiste en anticiparse activamente a los posibles problemas y resolverlos antes de que afecten al rendimiento o provoquen interrupciones.
En este proceso de supervisión, los datos de observabilidad de toda su infraestructura se recopilan, analizan y presentan de forma que ayuden a los analistas de datos y a los ingenieros de DevOps a mejorar la toma de decisiones.
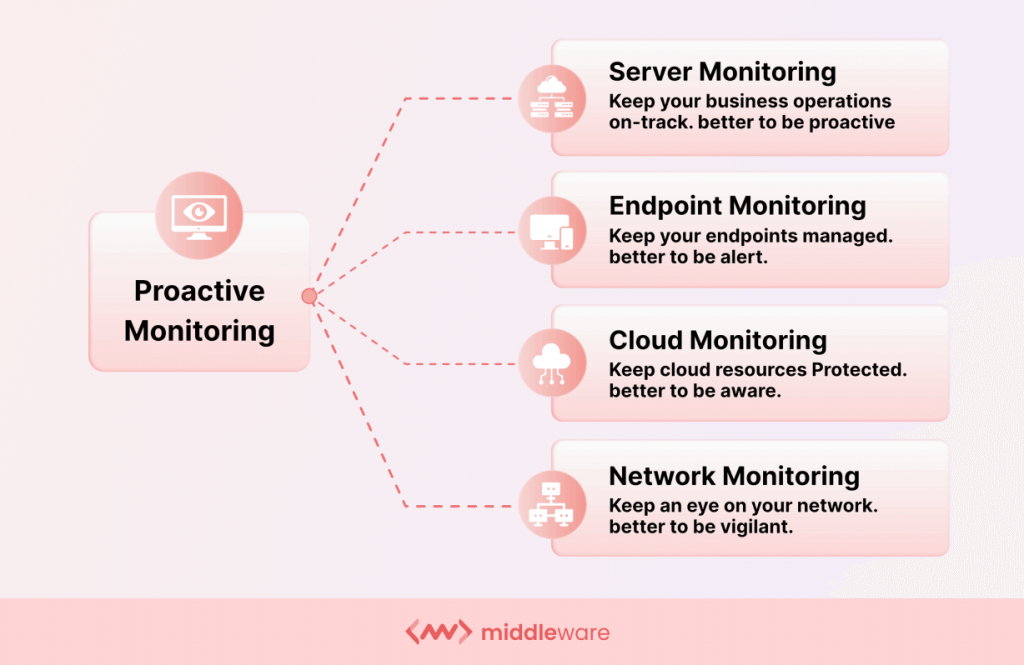
Control proactivo frente a control reactivo
El enfoque de supervisión proactiva aprovecha la capacidad de observación en tiempo real y las alertas para garantizar que los problemas o las desviaciones de los patrones previstos se detecten en tiempo real. Esto ayuda a los equipos de DevOps y a los analistas de datos a predecir problemas emergentes y cortarlos de raíz.
| Supervisión proactiva | Vigilancia reactiva |
| Anticipa los problemas antes de que se conviertan en incidentes críticos. | Está orientada a los incidentes, de modo que la actuación se desencadena por incidentes o interrupciones. |
| Los sistemas se supervisan continuamente en busca de parámetros de rendimiento, anomalías y señales de alerta temprana. | La supervisión de los sistemas puede realizarse según protocolos de mantenimiento programados. |
| La supervisión proactiva aumenta la fiabilidad general de los sistemas informáticos, reduciendo el tiempo de inactividad y mejorando la experiencia del usuario. | El modelo reactivo aumenta el riesgo de tiempos de inactividad prolongados, lo que afecta a las operaciones empresariales y a la satisfacción de los usuarios. |
| Se toman medidas proactivas para optimizar el rendimiento del sistema, lo que reduce la necesidad de una lucha reactiva contra los incendios. | Los equipos dedican un tiempo valioso a solucionar problemas que podrían haberse evitado con un enfoque proactivo. |
¿Por qué es importante la vigilancia proactiva?
La supervisión proactiva ayuda a mejorar el tiempo de actividad del servicio y el rendimiento general, ya que supervisa continuamente los sistemas para detectar posibles problemas. Este planteamiento tiene una serie de ventajas, como:
Ayuda a evitar tiempos de inactividad
La supervisión proactiva permite a las organizaciones identificar y resolver posibles problemas antes de que puedan causar interrupciones o afectar al sistema. Esto no sólo minimiza el tiempo de inactividad del sistema, sino que también garantiza que los procesos empresariales críticos continúen sin interrupciones y con un rendimiento óptimo.
Optimizar el rendimiento
Mediante la supervisión constante de los componentes del sistema, las organizaciones pueden identificar cuellos de botella, ineficiencias o posibles áreas de mejora. Este enfoque proactivo les permite optimizar el rendimiento global de su infraestructura informática.
Existen varias herramientas y servicios de supervisión de la nube que pueden ayudar a las empresas a obtener una visibilidad completa de su infraestructura y servicios basados en la nube, proporcionando alertas siempre que haya problemas que puedan afectar al rendimiento general del sistema.
Middleware proporciona una solución dedicada de observabilidad diseñada para supervisar y gestionar su infraestructura basada en la nube. Ofrece una visión holística de su infraestructura, aplicaciones y servicios, lo que permite una supervisión proactiva a todos los niveles.
Eficiencia de costes
Abordar los problemas antes de que se conviertan en críticos puede reducir significativamente los costes asociados a los tiempos de inactividad y las reparaciones de emergencia. La supervisión proactiva ayuda a controlar los gastos previniendo fallos importantes del sistema y sus consiguientes implicaciones financieras.
Aumentar la seguridad
Anticipar y mitigar las amenazas a la seguridad es parte integrante de cualquier sistema de supervisión proactiva o de gestión de alertas. Este enfoque protege los datos confidenciales y garantiza que cualquier infracción o actividad sospechosa se señale en cuanto se produce, lo que mejora el tiempo de respuesta y reduce los riesgos de ciberseguridad.
Planificación estratégica
La supervisión proactiva proporciona información valiosa sobre las tendencias del sistema y los patrones de uso. Estos datos pueden aprovecharse para la planificación estratégica, la gestión de la capacidad y la toma de decisiones informadas sobre la futura escalabilidad de las soluciones.
Cómo funciona la supervisión proactiva
En muchos sentidos, la supervisión proactiva ayuda a las organizaciones a funcionar con mayor eficacia y a minimizar los riesgos. Por esta razón, es natural que las organizaciones utilicen este enfoque para sus procesos DevOps.
Con una observabilidad y visibilidad avanzadas del sistema, los equipos de DevOps pueden crear procesos de sistema eficientes. Exploremos cómo se desarrolla en las cuatro etapas de la supervisión proactiva:
Supervisión
La primera etapa de cualquier plataforma de supervisión es establecer las herramientas y procesos que se utilizarán para la supervisión activa. Esto incluye la instalación del software, la configuración de los cuadros de mando y la definición de alertas o protocolos de supervisión del sistema.
Los desarrolladores y los equipos de DevOps lo utilizan para supervisar las métricas críticas, como los tiempos de respuesta de la API, el estado del servicio y el rendimiento de los datos. Los desarrolladores acceden a paneles en tiempo real para supervisar el rendimiento de sus microservicios. Pueden identificar al instante fluctuaciones en los tiempos de respuesta o variaciones inesperadas en el comportamiento de la API, lo que permite intervenciones y optimizaciones rápidas.
Registro de eventos
El registro de eventos es la siguiente capa, que captura los eventos y actividades críticos dentro de la arquitectura del sistema. Herramientas como Middleware registran eventos como despliegues de servicios, solicitudes de API y transacciones de datos.
Los ingenieros de DevOps pueden utilizar estos registros de eventos para comprender la cronología de las actividades y detectar al instante cualquier patrón inusual. Esto les permite rastrear la causa raíz del suceso, facilitando un diagnóstico y una resolución rápidos.
Rastreando
El seguimiento consiste en captar el recorrido de una actividad a medida que se desarrolla. Los equipos de DevOps suelen utilizar la ingesta y el análisis de registros para ayudar a rastrear anomalías y comprender cualquier patrón en el rendimiento del sistema que pudiera ser propenso a riesgos.
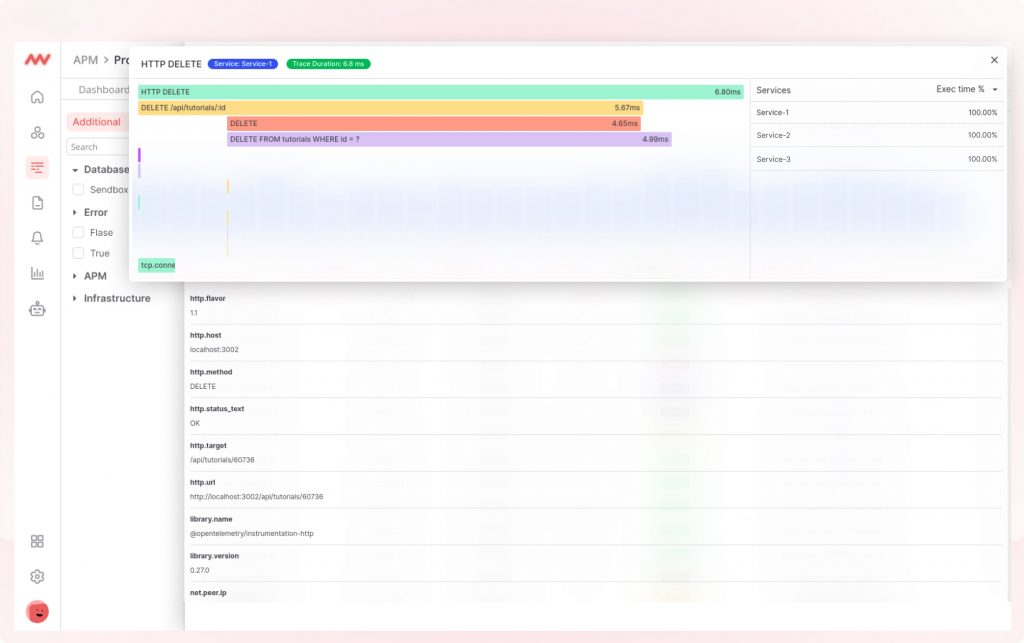
Por ejemplo, si un determinado proceso consume demasiadas peticiones o recursos, puede ralentizar el sistema en general e incluso provocar tiempos de inactividad. El rastreo permite a los ingenieros de DevOps seguir la ruta de una solicitud de API específica.
Si surgen problemas de latencia, pueden señalar los microservicios exactos que causan el retraso. Este nivel de granularidad ayuda a los equipos de DevOps a optimizar los procesos y mejorar el rendimiento general de la base de datos.
Alertas en tiempo real
Para la mayoría de los equipos DevOps, el enfoque general consiste en analizar y supervisar periódicamente los eventos. Este enfoque ayuda a comprender los procesos del sistema y a afinarlos para el futuro, pero cuando se detectan anomalías, el sistema debe notificarlas a los ingenieros de DevOps para reaccionar a tiempo. Aquí es donde las alertas en tiempo real desempeñan un papel crucial.
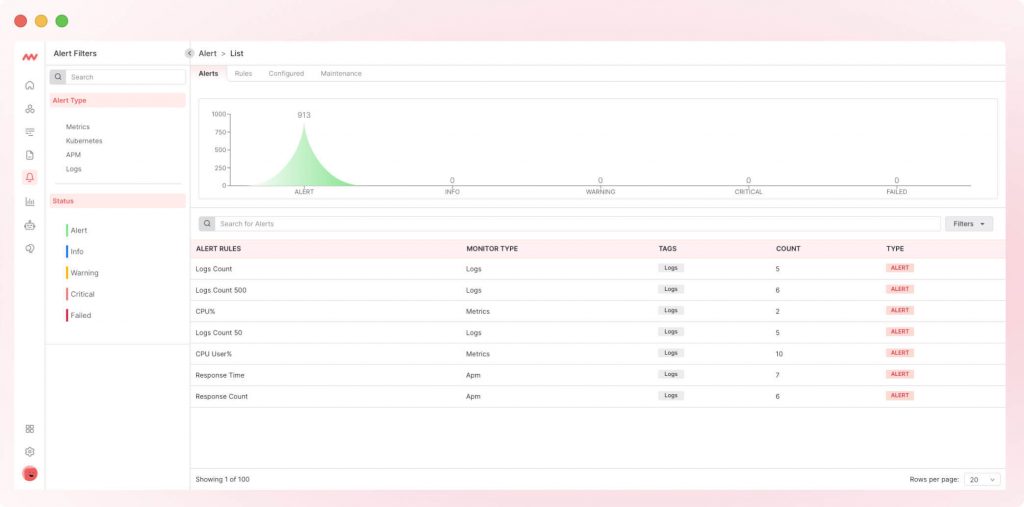
Por ejemplo, si la tasa de errores de una API supera el umbral establecido o detecta patrones sospechosos, puede emitir alertas a tiempo. Esta notificación proactiva permite a los equipos de DevOps responder con rapidez, garantizando la fiabilidad y disponibilidad de los recursos del sistema.
Buenas prácticas de supervisión proactiva
Ahora que ya sabemos cómo funciona la supervisión proactiva, conozcamos las mejores prácticas para aplicarla.
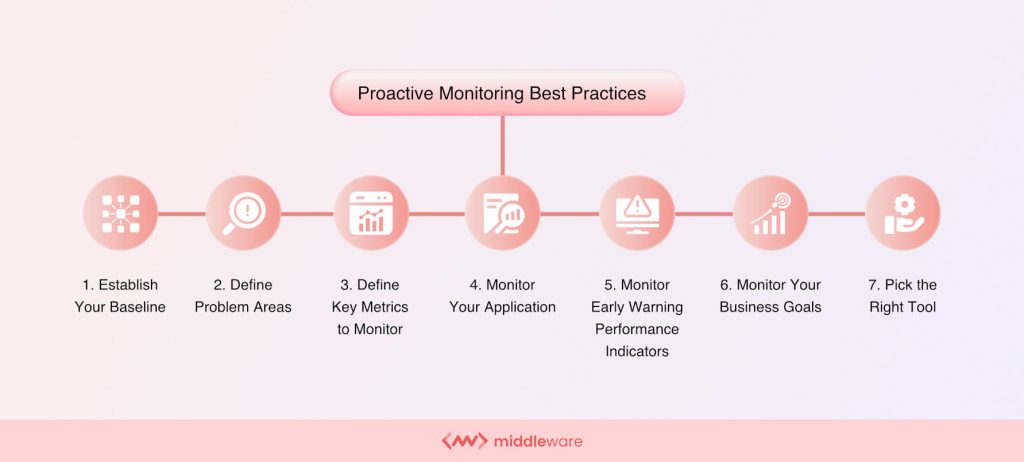
1. Establezca su línea de base
Establecer una línea de base saludable significa saber qué es un comportamiento saludable para su sistema. Antes de implantar la supervisión proactiva, establezca una línea de base para el comportamiento normal del sistema.
Para ello, debe aplicar prácticas de observabilidad en su sistema y permitir que funcione con normalidad durante un periodo de tiempo determinado. Durante este tiempo, observe las fluctuaciones que se produzcan y anote las razones de las mismas en caso de que se produzcan problemas o anomalías, y anote qué patrones se dan cuando ocurren estos incidentes.
Estos datos le ayudarán a establecer una línea de base saludable y le servirán como punto de referencia para identificar anomalías y posibles problemas.
2. Definir las áreas problemáticas
A continuación, defina las áreas problemáticas o los componentes de su arquitectura que deben señalarse. Trabajar en estrecha colaboración con los equipos de desarrollo, operaciones y negocios para identificar las áreas que son propensas a problemas de rendimiento o que tienen un impacto significativo en la funcionalidad general del sistema.
3. Definir las métricas clave a controlar
Una vez definidas las áreas problemáticas, también hay que proporcionar indicadores clave de rendimiento (KPI) que se ajusten a los objetivos generales. Ya se trate de tiempos de respuesta, tasas de error o utilización de recursos, la selección de métricas pertinentes es crucial.
Dependiendo de la métrica que elija, la estrategia de seguimiento se adaptará y se centrará directamente en la métrica. Estos KPI definirán con exactitud el rendimiento y la fiabilidad reales de su sistema, por lo que se trata de una decisión crucial.
4. Supervise su infraestructura
Incluya la supervisión de la infraestructura como parte de su estrategia proactiva. Esto incluye la aplicación de las mejores prácticas de Observabilidad que proporcionan un conjunto de directrices para que el sistema cumpla las normas y el comportamiento esperado.
Vigile la salud del servidor, el rendimiento de la red y otros componentes de la infraestructura que soportan su sistema. Esto garantiza que los problemas originados por la infraestructura subyacente se identifiquen y resuelvan con prontitud.
5. Supervise su aplicación
Más allá de la supervisión a nivel de infraestructura, también es necesario supervisar el estado de las aplicaciones y los servicios que se ejecutan en este sistema. Rastree el comportamiento de cualquier aplicación, API o servicio relevante que se ejecute en el sistema. Esto incluye la supervisión de la ejecución de código, las consultas a bases de datos y las integraciones de servicios externos.
Si se omite algún componente o aplicación, pueden producirse anomalías que la herramienta de supervisión no será capaz de detectar, lo que dará lugar a problemas.
6. Supervisar los indicadores de resultados de la alerta temprana
Una vez definida una línea de base saludable, implante sistemas de alerta temprana que supervisen las métricas definidas y emitan alertas cuando se detecte cualquier anomalía. Este enfoque proactivo permite intervenir a tiempo y evita que los problemas menores se conviertan en trastornos graves.
7. Supervise sus objetivos empresariales
Por último, los indicadores clave de rendimiento (KPI) no son sólo una referencia del estado y el rendimiento del sistema. También le ayuda a controlar sus objetivos empresariales y a comprender el rendimiento de su sistema. La supervisión no debe centrarse únicamente en las métricas técnicas, sino también en la correlación directa entre el rendimiento del sistema y la consecución de los objetivos empresariales.
8. Elija la herramienta adecuada
La aplicación de estas mejores prácticas de supervisión proactiva permite a las organizaciones anticiparse a posibles problemas, optimizar el rendimiento del sistema y alinear los esfuerzos de TI con objetivos empresariales más amplios. Pero el elemento crucial de todo esto es elegir una herramienta de supervisión que se adapte a los requisitos y la tecnología de su empresa.
Ya sean soluciones de código abierto, herramientas comerciales o una combinación de ambas, asegúrese de que la herramienta elegida ofrece la flexibilidad y escalabilidad necesarias para adaptarse a la complejidad de su infraestructura.
Las 3 mejores herramientas de supervisión proactiva
Hay varias herramientas disponibles en el mercado que pueden ayudarle a implantar una supervisión proactiva en su infraestructura. Para ayudarte a tomar una decisión informada, aquí tienes las tres herramientas de monitorización más recomendables:
Middleware
Middleware es una plataforma de observabilidad en la nube de pila completa que se especializa en proporcionar observabilidad de extremo a extremo para aplicaciones complejas y de múltiples capas. Esto aporta características únicas, como:
- Una completa plataforma de observabilidad diseñada específicamente para gestionar sistemas complejos y de varios niveles.
- Monitorización en tiempo real para realizar un seguimiento de las métricas vitales y los KPI de DataOps.
- Funciones avanzadas de seguimiento del flujo de ejecución de las transacciones para identificar cuellos de botella y optimizar el rendimiento.
- Registros de eventos para capturar y analizar eventos críticos, proporcionando una línea de tiempo detallada para la resolución de problemas.
- Capture las acciones críticas para el negocio, como los clics en la caja, para tomar decisiones informadas.
Datadog
Datadog es una plataforma de monitorización y seguridad en la nube que le ayuda a monitorizar trazas, métricas y registros para que su aplicación, infraestructura y servicios de terceros sean totalmente observables. La herramienta ofrece funciones de supervisión completas y proactivas, como:
- Visibilidad de extremo a extremo de toda la pila, incluida la infraestructura, los servicios y las aplicaciones.
- Cuadros de mando personalizables para supervisar las métricas clave y los indicadores de rendimiento.
- Alertas basadas en IA y algoritmos inteligentes de autoaprendizaje para alertas inteligentes basadas en patrones y desviaciones anormales.
Logz.io
Logz.io es una plataforma de monitorización y observabilidad de código abierto de 360 grados que funciona con OpenSearch (análisis de registros), Prometheus (análisis de métricas) y OpenTelemetry (análisis de trazas). Esta solución única incluye funciones como:
- Gestión de registros nativa de la nube, lo que la hace idónea para las aplicaciones modernas en la nube.
- Supervise los registros en tiempo real para detectar rápidamente anomalías, errores o incidentes de seguridad.
- Funciones avanzadas de análisis de seguridad y detección de amenazas para proteger los entornos de middleware.
- Ideal para equipos que dan prioridad a la supervisión y solución de problemas centradas en los registros.
Conclusión
La supervisión proactiva desempeñará un papel crucial en cualquier infraestructura informática y es ya una tendencia creciente en la supervisión de infraestructuras. A medida que evolucione, el análisis predictivo, el aprendizaje automático y la IA contribuirán a mejorarla aún más. Esto puede ayudar a las organizaciones a llevar la supervisión proactiva aún más lejos, simplificándola y automatizándola en el proceso.
Así pues, las tendencias futuras en materia de supervisión proactiva pueden ayudar a las organizaciones:
- Reduzca el tiempo de inactividad identificando los problemas antes de que puedan afectar al sistema.
- Mejore el rendimiento identificando los problemas de rendimiento en tiempo real.
- Aumente la seguridad supervisando constantemente el sistema para detectar cualquier amenaza.
Para implantar la supervisión proactiva y la gestión de alertas, es crucial seleccionar las herramientas adecuadas. Evalúe sus requisitos específicos, infraestructura y limitaciones presupuestarias para tomar una decisión informada basada en las prioridades de supervisión de su organización.
Con la herramienta adecuada, puede asegurarse de que la supervisión proactiva se implanta de forma eficiente en su organización y se alinea a la perfección con sus objetivos empresariales.
Empiece a utilizar Middleware de forma gratuita para obtener las ventajas de la supervisión proactiva y medir las métricas en tiempo real.
Leave a Reply